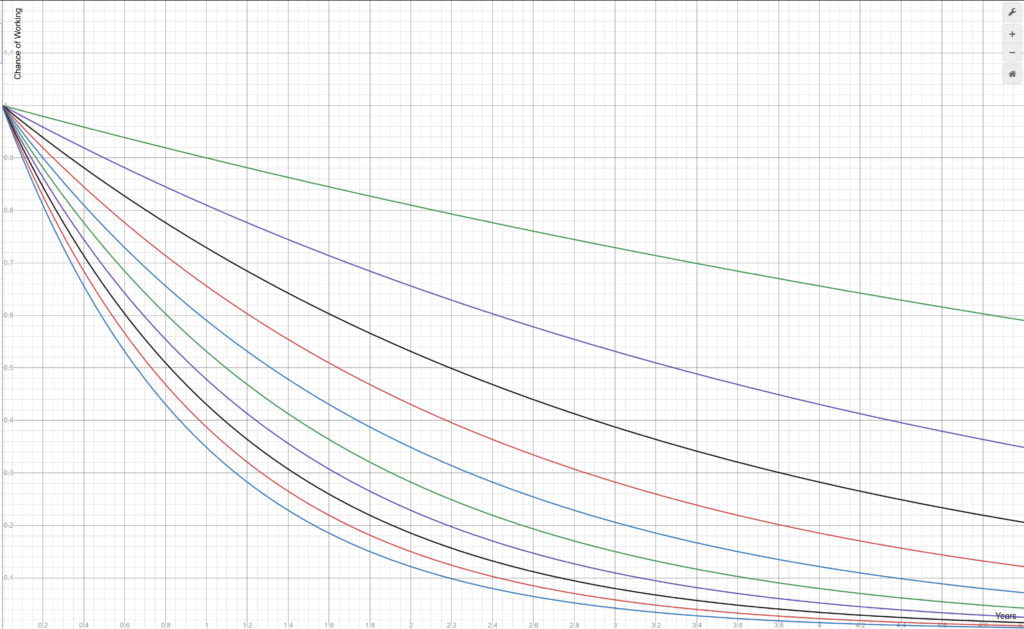
If we take the chance that a tool (compiler, linker, batch, whatever) remains working for a particular codebase after one year as a given probability p, then the chance that build remains working after x years is pxn, where n is the number of tools used in the build.
That’s “just math”. Even if we assume a 99% chance that a tool still works on the codebase after a year (an extreme rarity these days!), that graph looks like this:
With just one tool, the build has an over 95% chance of working after five year. With ten tools, it has only a 60% chance! And that’s with every tool having a _99%_ chance of remaining working (meaning no breaking changes to the tool that affect the build in question).
If we assume a still probably favorable given today’s environment, but slightly lower p of 90%, the graph now looks like this:
This is, of course, an epic disaster. With just 3 tools used, after 5 years there is _very little chance_ that your codebase will still build correctly. And that’s at 90% and just 3 tools!
If you look at 90%/10 tools, heaven forbid, that bottom line says your build almost certainly doesn’t work after only 2 years… and in fact has barely a 30% chance of working after just 1 year!
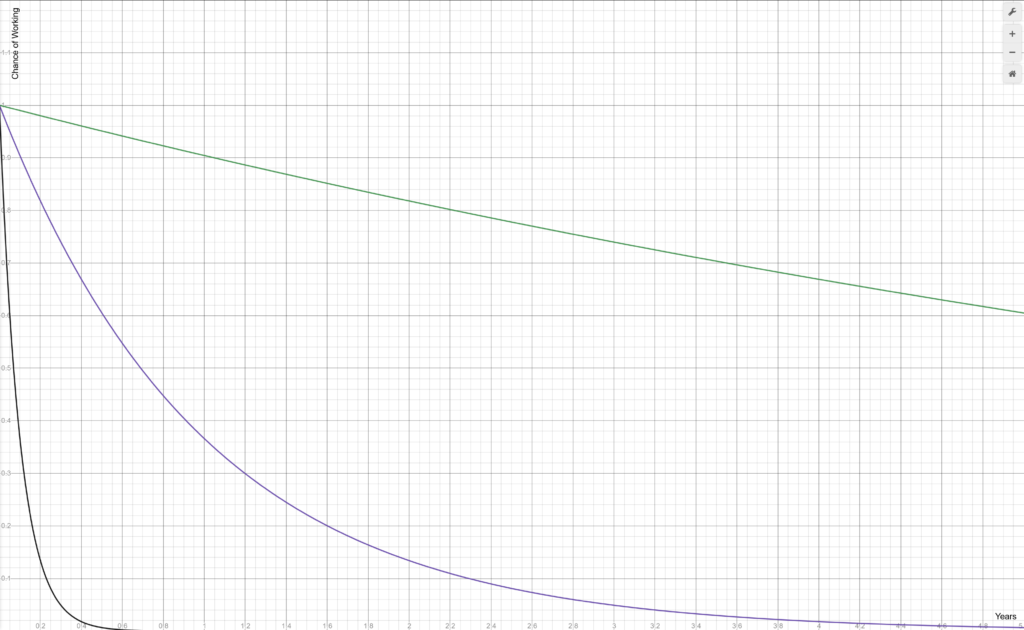
Now imagine that we don’t say “tool”. We just say “dependency”. The equation _remains the same_. Modern codebases often have 10s, 100s, or even 1000s of dependencies! What does that do to this graph?
Here is the graph of 10, 100, and 1000 dependencies, assuming a never-happens-on-github percentage chance of a dependency not breaking your build at 99%:
10 dependencies sort-of works. It has a 60% chance of still working after 5 years. 100 dependencies doesn’t work. It’s less than 40% after just 1 year. 1000 dependencies breaks with almost complete certainty after a mere _four months_.
All of this is already something you know intuitively. Projects with lots of dependencies never work out-of-the-box. You are constantly updating, patching, and struggling to get their builds working, because every time something downstream changes, somebody has to fix it.
The “dependency culture” of modern programming has put us into a state where software requires perpetual, constant maintenance. No longer can we take a build and say “this works” and come back to it in a year. Great for job security, horrible for software quality.
As for speculation, I wonder, at least in part, if this answers the questions me and other people like me have, which is how do companies like Twitter employ thousands of developers while seemingly producing almost no additional software or improvements?
Well, if you assume that Twitter’s collective codebase is a 1000+ dependency nightmare, as I assume it probably is, then the math kind of tells us the answer: the vast, vast majority of their time will have to be spent simply keeping their existing code working.
As engineers we are often given a list of requirements from someone else. We just accept them and start trying to design. We trust that other people know what they’re doing in part because our entire educational career we could never question the premise of a problem. The teacher says “Solve this” and you solve it – you don’t get to say “This is a dumb question” (Unless you’re fine failing as I was with Prof. Dempsey in Calc 3)
Musk goes on to say that in order to allow people to question the requirements, there’s another rule that goes along with this one.
1.a All requirements must have a person associated with them, not a department.
You can have a reasoned argument with a person but try arguing with a “department” and you’ll soon find yourself in a Dilbert Cartoon.
2. Delete the part or process
If you are not occasionally (say 10% of them time) adding things back in, then you aren’t deleting enough.
3. Simplify or Optimize
The most common error of a smart engineer is to optimize a thing that should not exist.
Once you have less dumb requirements, and you’ve eliminated as much as you can from the design only then try and optimize what’s left. These first 3 rules are really trying to get at one problem. The problem of really smart engineers trying to optimize the system they’ve been given rather than thinking about things from base principles and then optimizing. We tend to jump to optimization.
Only once all the other steps are complete, only then should we then try and automate a process. Doing it this way unlocks a few really nice properties. Automation takes longer to setup and get working but pays dividends in the future. However, those dividends only come if you’ve automated the right thing.
One of the things I find the most difficult to teach is the discipline to solve exactly the problem that is in front of you, and only that problem. Solve it in the simplest way you can think of. Be confident that in the future if new requirements arise, such as improved performance, you’ll be able to make a “better” implementation to account for the new requirements. Then move on to the next real problem.
I think this is kind of like the joke that if you ask a lawyer if they know the time, they’ll say “Yes”.
Another way to say this might be: Solve real problems, not imaginary ones. It can be difficult to tell the difference. Our brains are equipped with a simulation engine that allows us to imagine things that aren’t really there. Imagine a sparrow with orange stripes. If you don’t suffer from aphantasia then you likely saw exactly what was described. What you might not have noticed is that while you saw the bird, the real world blanked out. The simulation engine takes over our real senses to run its simulation. You can imagine something scary and you will be scared even though it is not real.1 In this same way the problems you think of can feel real. This is an illusion and the way to combat that is to say you’ll only work on problems that have real evidence, a real example, an actual data set, not imagined scenarios.
Ask yourself: “Is this requirement real or is it just a thought?“
“Yes, but you only have to implement it once! So you should take the extra time to do a good job!”
That assumes you’ve correctly predicted the future and the code is used exactly the way you thought it would be. If you have this ability and care at all about money, you should be playing the stock market and not writing code for other people. I have learned the hard way that I do not. I’ve implemented complex solutions that took a long time to write only to discover that some requirement I didn’t think of has broken it completely effectively requiring a redesign to handle the new scenario.
This is how I code. I work this way because I’ve discovered that I’m not particularly good at predicting the future. I can imagine all kinds of problems that are not real, they’re just thoughts. Trying to account for all of these imagined problems leads to very complex solutions. Complex solutions are difficult to reason about, difficult to implement correctly, take more time to implement than simpler or more naive solutions. They are more difficult to debug and fragile to changing requirements (the ones you didn’t imagine).
Practically what I’ve found is that sometimes the naive implementation is all you need. It’s sufficient for the problem sizes you’re dealing with, and you saved yourself a ton of time by not implementing something more complicated with better performance. You were able to move on to add more value to the project quickly because you implemented an N^2 algorithm in a hour instead of taking a week to write a much more complex solution. And it was fine. If it isn’t fine, then you’ll know that pretty quickly, and you’ll have actual evidence to justify taking the time to create a more complex implementation. You can point to the real data you’re trying to process and say “this is the reason I need more time”.
I am starting to wonder if this is something that can even be taught. Is this a conclusion one needs to come to on their own? Through their own experiences. After all, that is how I have come to this philosophy.
I have, on several occasions, had more work than I could possibly do under tight deadline. The argument that deadlines are arbitrary falls on deaf ears when you are burning cash and have no product to sell. Working code today is better than perfect code tomorrow. What good is perfectly written code that nobody uses? Nobody uses it either because it wasn’t what they actually needed to solve their problem (you predicted wrong, but spent a long time implementing the wrong thing), or worse your company no longer exists because it blew through all it’s cash before you could make a single sale.
While we could go back and forth about the benefits of a strict adherence to any programming philosophy: Static vs Dynamic, Agile vs Big Design Up Front, Types vs Tests, DDD, CQRS, TDD, etc. One thing I will say is that if you want to get better at this discipline, I think that some amount of Test Driven Development is the best way to practice this.
This is by far the topic I get the most push back from engineers about. Even more than Software Engineering is Writing. They always want to go slower, more carefully. The idea of doing what they’re doing now but faster seems crazy. It is crazy. You can’t go faster doing what you’re doing now. Instead I want us to change what we’re doing to go faster.
Why should we be trying to go faster? In short, because we’re professionals.
Professionals vs Hobbyist
Activity
Professional
Hobbyist
Driving
200 MPH
65 MPH
Football QB decision to pass or run
3 sec
10 sec
Cleaning a 1br Apartment
4 hr
1 day
Baseball fastball
90 MPH
50 MPH
Programming – implementing a single screen of a prototype UI
1 month
2-3 days
An almost universal difference between a professional and a hobbyist in every job is speed. Professionals are faster than amateurs.
Most of the above data comes from the book “Wait: The Art and Science of Delay” by Frank Partnoy. The title is an interesting choice as the main argument I get out of the book is: Focus on speed. Speed allows you to wait longer to take action. Waiting longer allows you to gather more information, which increases the likelihood of a better outcome. It reminds me of the Special Forces phrase: “Slow is smooth and smooth is fast”.
The last line in the table comes from a friend at Google. They told me this is how long it takes them to make a single prototype screen for a UI. I nearly spit out my coffee. I chose this because the majority of programmers I talk with are Googlepheliacs who think everything they do is “the way” and should be emulated always, everywhere.
Speed of what?
If you want a metric, the one I’m currently using is: Working software, in the hands of customers, as quickly as possible with as low a defect rate as possible.
Another valid approach might be something like: minimizing median time to feedback.
But won’t quality suffer?
No, I don’t believe so.
It might at first, as people who are used to driving their car straight until they hit a guard rail realize they might actually have to learn how to drive. But on the whole I believe the quality of your programming skills increase faster with the quantity of finished products more than slow reasoned debate. If that’s true then the faster you build products, the faster your skills develop.
The following story illustrates the impact of speed on quality:
The ceramics teacher announced on opening day that he was dividing the class into two groups. All those on the left side of the studio, he said, would be graded solely on the quantity of work they produced, all those on the right solely on its quality. His procedure was simple: on the final day of class he would bring in his bathroom scales and weigh the work of the “quantity” group: fifty pounds of pots rated an “A”, forty pounds a “B”, and so on. Those being graded on “quality”, however, needed to produce only one pot – albeit a perfect one – to get an “A”. Well, came grading time and a curious fact emerged: the works of highest quality were all produced by the group being graded for quantity. It seems that while the “quantity” group was busily churning out piles of work – and learning from their mistakes – the “quality” group had sat theorizing about perfection, and in the end had little more to show for their efforts than grandiose theories and a pile of dead clay.
“Ok, I’m not gonna click on any of that, but how would you propose we accomplish this?” I hear you say. Well, I have some thoughts…
Work on the problem in front of you
Stop trying to predict the future (“future proofing systems”) and just solve the problem you’re trying to solve with the minimal amount of code necessary. The current approach is hurting in the following ways:
We’re all bad at predicting the future, so what you write may never be necessary.
It takes more time to write the future proof version of the code.
Creating flexibility requires abstraction. This abstraction is implemented through indirection. Every layer of indirection adds cognitive load that is unnecessary and unrelated to the task (sometimes called incidental complexity).
Good abstractions are difficult to make correctly and require lots of examples to do well.
Repeat Yourself
A little bit of code duplication is better than maintaining 20+ abstract types.
I use the Rule of 3: I will copy and paste the same code twice. Once there is a third concrete need for that same code, I then feel like I have enough information that the likelihood of creating the appropriate abstraction is high.
Don’t Break Tools!
Two years ago I quit my job and decided to strike out on my own. Since I was programming for myself, I thought there’s no harm in using a programming language I love and had used to great success in production elsewhere, and so I wrote everything in F#. I truly believe that F# is the best language on the .NET platform and has the superior programming model for eliminating entire categories of bugs (no null, for example). I believed the strong type checker would help me move more quickly than in C#.
I was wrong, but not for the reason I originally thought. For the last 6 months I’ve moved back to C# for only one reason. Tooling. All of the tooling around C# really increases your productivity with the language despite some of the issues around null, verbosity around types, etc. in F# I had to write the simple database migrations myself or otherwise jump through hoops to have a single C# project linked to my F# project so that EF Core would do the magic. The same thing is true for writing mobile apps with Xamarin. The tooling for C# ‘just works’, while for F# there’s a lot of gotchas and edge cases that you need to figure out.
The time to go from idea to working code either in the browser or on my mobile device is shorter with C# because of the tooling aiding me in writing correct robust code.
So this has changed my language stack-rank. I’ve found it’s preferable to use the ones with the best tools. Modern IDEs, debuggers, profilers, static analysis tools all help you immensely to speed up the time it takes to write correct, robust code. If you’re not using them, then you don’t even know what you’re missing. I like VIM as much as the next person, but it doesn’t hold a candle to Visual Studio or IntelliJ in terms of productivity.
Yet in almost every large project I’ve worked on, no matter the language, someone has broken the tooling. Usually the culprit is the build. They’ve put things in non-standard directories and then write their own build script to re-assemble everything in the correct place for CI… but I wish they had just taken the time to get it working for everyday developers in the standard tool.
Testing and Other Quality Control
I’ve heard arguments from the TDD crowd that although testing requires more upfront work it actually makes you go faster. This is not born out by the evidence in the book “Making Software: What Really Works, and Why We Believe It” by Andy Oram, Greg Wilson which is as close as I’ve been able to find to someone using the scientific method to measure things about software engineering processes. You can quibble about the testing methodologies of the underlying papers, but it’s still peer reviewed and published data, which is better than any blog post, including this one.
Testing absolutely helps when a project is so large you can’t keep it all in your head, but it’s not an unalloyed good. Testing makes permanent. Maybe that’s what you want, but maybe it’s not. How can we tell the difference? A maturity model of software is useful here.
A Maturity Model of Software
I think it’s obvious on its face that not all software is created equal. Software that crashes is probably fine for a prototype of an Instagram clone – but not so much for avionics or automobiles. But the thing people seem to struggle with is the idea that different code within the same organization can be at different levels of maturity at the same time.
It doesn’t make much sense to enforce all of the quality gates that business critical software uses on prototypes or experiments. The first iteration of a new feature should be shipped to customers at prototype quality until such time it is proven valuable to customers. It is proven when people are actually using it, or better paying for it. Labels like Beta are helpful for signalling to customers that this is an experiment, allowing them to decide if they only want the stable stuff.
This minimizes mean time to feedback, and if you’ve built the wrong thing you didn’t waste 6 months making it rock solid just to have it fail in the marketplace. You’ve learned it was not viable for way cheaper. I’ve learned the hard way in my career that Field of Dreams development – “If you build it, they will come” – is NOT true.
The following three sections outline example properties of software at different maturity stages, from least mature to most mature.
Prototype/Experimental Software
Key properties include:
Customers are internal initially
Speed to customers/mean time to feedback is the most important metric
This is more important than code coverage metrics
Few automated tests or build guarantees
It takes time to write tests, but even MORE time to unwrite them when you realize you’ve made the wrong thing. Make sure you’ve built the right thing first, then add automated tests once that is proven.
Doesn’t need to follow the style guide yet if the guidelines propose onerous requirements for uses of frameworks, OOP design patterns, etc.
If it’s easier to access the database without the ORM, then do that
No onerous secrets management or storage
If it is a feature worth keeping then rotate the keys when that’s proven. Until then, check them into the repo. These keys have been designed to be easy to rotate, so stop worrying about making it so they never get leaked and instead focus on making them easy to change, should that happen
No encrypted network traffic
TLS and Secrets Management combine to make the day to day lives of developers a living nightmare. They aren’t necessary for a feature that hasn’t shipped to customers yet, so stop shooting yourselves in the foot requiring every developer to jump through 20 hoops before they can get a single line of code working.
Performance not an issue
Get it working correctly first in the simplest way possible. You might not actually need more, and if you do you’ll figure that out too.
Beta Software
This software is exactly the same as the prototype software upon first release, except that it is made available to a select few external customers. The software then incrementally matures towards critical software maturity as it is more and more proven out. Properties include:
Performance optimizations for hot paths
Begin adding automated tests for features that have market fit
Remove or rewrite features that no one is using based on data
Implement stricter security
Accessibility concerns are addressed in this phase
Improved logging and error handling
Critical Software
This is the software that makes you money, and when it goes down it affects revenue and presumably your bonus/stock valuation
Strong automated testing with CI/CD gates
Blue/Green deployment controls
Logging
Secrets management
TLS encryption on network communications
PII Encrypted at rest*
Good Security hygiene
Accessible
The key here is to apply this model not to the entire organization, but project by project or, even better, feature by feature.
This is not a new concept, although the above definitions are my own and are far from exhaustive. This idea is actually used by the the US Governement where they call it Capability Maturity Model (CMM). There are several version of CMM, and I am sure others have created many more.
If you have one you like, think I’ve left out your favorite property, or have any other thoughts let me know in the comments!
*You should always follow all local laws and regulations… maybe. I mean, Uber and AirBnB seem to have had their businesses impacted very little by flouting local laws but, what do I know IANAL
I think the people who liked the above tweet think I’m being funny by choosing a cake instead of a pie; that I’m suggesting that cake is superior to pie. But I’m actually being serious – Cheesecake is a pie not a cake.
When you make pumpkin pie, you make the crust, then the filling; you pour the filling into the crust and then bake it. When you make cheesecake you make the crust, and then the filling, then you pour the filling into the crust and bake it. With cake, you typically mix everything in a big bowl, pour it into a pan and bake it as is – no crust, no filling. You see, just because cheesecake is called cake doesn’t mean it actually is cake.
Words matter. They affect the way we think about things. When something is mislabeled, or we use an inappropriate metaphor, it can lead to lots of misconceptions down the road as people try to reason about it with the mental model in their head that the name invokes.
I think this has happened to Software Engineering. After 20 years in the industry, and having earned an engineering degree, I think I can now safely say that almost none of what we do is engineering. It’s writing, similar to any kind of writing that uses a team, like television writing. This mislabeling has caused a great deal of confusion for many, many years about why our industry doesn’t seem to work like any of the other engineering disciplines. But perhaps more importantly, the engineering label has limited our thinking about both the field itself and important things related to the field such as compensation models.
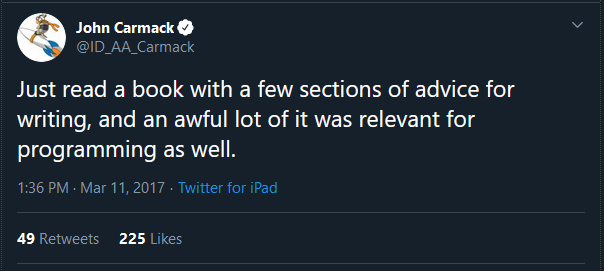
A personal hero, John Carmack, might agree with this. In 2012 during one of his infamous QuakeCon keynotes John Carmack said:
“… It’s nice to think of myself as a scientist/engineer sort dealing in these things that are abstract or provable or objective… and in reality, in computer science just about the only thing that’s really science is when you’re talking about algorithms and optimization is an engineering task …
… But 90% of the programmers are doing programming work to make things happen, and when I start really looking at whats going on in all of these, there really is no science and engineering and objectivity to most of these tasks …
… we like to think [that] we can be smart engineers about this, that there are objective ways to make good software. But as I’ve been looking at this more and more, it’s been striking to me how much that really isn’t the case. That aside from these things that we can measure, measure and reproduce — which is the essence of science, to be able to measure something, reproduce it, make an estimation and test that — and we get that on optimization and algorithms. But everything else we do really has nothing to do with that, and it’s about social interactions between programmers or even between yourself over time …”
I think that if I’m honest with myself, I agree with everything he’s saying, and actually this talk is the one that made me really start thinking about this.
What would it mean to be a Software Writer rather than a Software Engineer?
Writing and Translation
I think looking at software as an act of both writing and translation would explain a few things. Like why as an industry we’re notoriously off when trying to estimate how long things take. Just like fiction authors are typically over deadline. I mean how long would it take you to write a chapter of a book? How about a good chapter?
That to me sure feels the same as: How long will it take to implement feature X? What if we want it to be a ‘good’ feature?
What does it mean to write “good” code? What does it mean to write good prose? I’ve often felt that much of what people say are good coding practices are pretty arbitrary or a matter of style or personal preference. I felt the same way in English class when we talked about the rules for good writing.
“All writing takes the same amount of time. If you’ve thought a lot about what you want to say, it flows easily.”
– Jessica Hibbard, Head of Content and Community, Luminary Labs
The quote above reminds me of an argument I often hear from a certain class of programmer. They want people to stop and think more before they write code. Typically I hear this from the functional programming types, but I’ve heard it in other contexts.
Seeing software as language and writing would probably make it more appealing to women. For decades the number of women studying computer science was growing faster than the number of men. But in 1984, something changed. That thing was to make computer science appear to be more mathematically based.
Compensation
The parallels between writing and programming don’t stop there. When you write a book, all of the effort is upfront and then once it’s complete you can sell an unlimited number of copies. Does that sound familiar?
That model also applies to TV shows and movies. One thing all of those industries has in common? The writers get royalties.
I think software writers should get royalties too. I have code in Visual Studio from 2010 that is still shipping today long after I’ve left Microsoft. I’ve written software for traders to manage the risks on large portfolios, more volume than any human could keep track of themselves and yet the traders received the huge bonuses and I got nothing. I wrote a good chunk of the order processing system for Jet.com, a system which processes millions of dollars in orders every day and I didn’t even get a choice about keeping my stock or not when it got sold to Walmart. All of that code is still running, producing value for those companies and BONUS they don’t have to pay me anymore since I don’t work there.
If software was seen as writing then, for those people who want to (Google employees?), they could join the writer’s guild rather than trying to unionize workplace by workplace.
What do you think? In what other ways is writing software more like writing other media? Let me know in the comments.
Update:
After a discussion over on reddit about this piece I’ve come up with even more ways in which software is like writing.
Update2:
Since people keep reading, I’ll keep writing or clarifying things as they come to me. Appreciate the comments!
More Similarities to writing
Software projects can be successful without good engineering, just like books can be successful without good writing.
Following all the rules and best practices in software do not guarantee success of a software project any more than following all the rules of grammar will make your book successful. In fact I’ve never seen any published paper that shows any correlation between the two. Would love to read it if someone has it.
New ideas implemented in software (Google page rank, Uber, etc.) influence the real world as much as books like The Communist Manifesto, or The Prince did. I’d be willing to wager Excel has fundamentally changed as many economies as The Communist Manifesto did.
Video game developers seek publishers that do exactly the same thing as publishers in the book industry do.
“Good” code from 1998 (when I started) looks very different from “Good” code in 2019. “Good” writing from 1886 looks very different from “good” writing in 2019.
Some authors are better writers than others at coming up with eloquent ways to say things, just like some programmers are just better at coming up with elegant solutions.
Code reviews sure look a lot like sending your writing to an editor.
Consequences if true
If the analogy to writing is closer than the analogy to engineering, then to become a better software writer/author one should look to the tools that writers use to become better writers rather than to other engineering disciplines.
Software being like writing would also explain (to me) why the many attempts I’ve seen to bring more rigorous, formal processes, like those in other engineering disciplines, has failed so consistently over the last 20 years. Software just doesn’t need to be an engineering discipline in order to be successful. Usually the explanation for this is that this is some new kind of engineering the world hasn’t seen before. Between the competing theories that SE is somehow a new engineering discipline that conveniently doesn’t seem to work like any other engineering discipline and the theory that it is not engineering at all. Occam’s Razor would dictate the simpler “not actually engineering” is the better theory until proven otherwise.
Update 6/14/2020
Now confirmed by science with brain scans and published in the ACM: