You think Tech CEOs will still be testifying in front of congress about the STEM shortage and the desperate need to increase H1B visas again this year?
Activity Stream
-
-
Luke, I’m heading to Toshi Station. You want me to pick up some power converters?
-
Anyone who grew up in the 80s will remember going on a road trip, even a short one, and the front windshield would be COVERED in dead insects
Did you notice that doesn’t happen anymore? You’re not imagining it
https://en.m.wikipedia.org/wiki/Windshield_phenomenon
-
Future historians and archeologists are going to think we worshiped an entire pantheon of gods:
* Iron Man the God of Technology
* Hulk the God of Rage
* Captain America God of America
* All the other minor Gods
* Thor somehow still the God of Thunder
-
I invented a new sandwich at my local deli! It is super delicious. I think they’re going to name it after me
Only later to realize it’s just a Burger King original chicken sandwich with deli ingredients and extra steps 😭😭😭
-
-
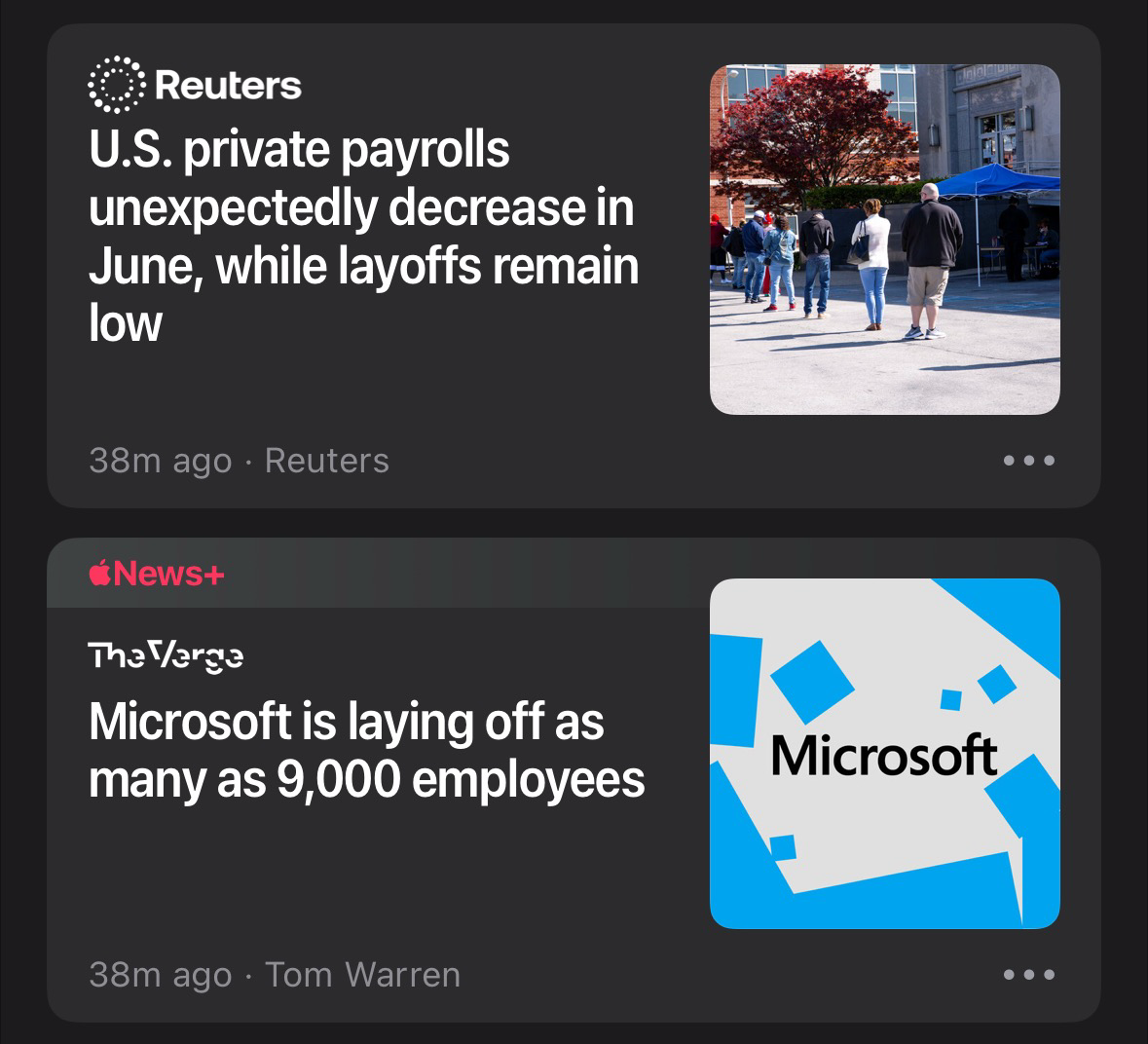
Unexpectedly
-
Threads ProTip
You can use VIM key bindings to browse threads on web.
J – select next threadK – select previous thread
L – Like
R – Reply
P – new post
Q – Quote thread
🌈⭐️
-
The tough job market for new college grads probably isn’t all due to AI
Current Job Market Reality
- Unemployment for college degree-holders aged 22-27 is almost 6%, the highest since the pandemic
- This rate is significantly worse than the overall unemployment rate of 4%, creating an unusual inversion rarely seen in the past three decades
- Recent graduates are struggling to find work despite having degrees, with some considering service jobs while waiting out the market
AI’s Role (Mixed Impact)
- Only about 6% of firms across the economy have adopted AI technology according to Goldman Sachs The tough job market for new college grads probably isn’t all due to AI
- In tech specifically, AI impact is more significant – new graduate hires by Big Tech fell 25% since 2023
- AI can now handle entry-level coding tasks that were traditionally learning opportunities for junior developers
- Tech companies increasingly brag about AI-generated code while simultaneously announcing layoffs
source: https://www.marketplace.org/story/2025/06/30/why-college-grads-are-struggling-to-find-work