

Unrolled Tweet Thread
If we take the chance that a tool (compiler, linker, batch, whatever) remains working for a particular codebase after one year as a given probability p, then the chance that build remains working after x years is pxn, where n is the number of tools used in the build.
That’s “just math”. Even if we assume a 99% chance that a tool still works on the codebase after a year (an extreme rarity these days!), that graph looks like this:

With just one tool, the build has an over 95% chance of working after five year. With ten tools, it has only a 60% chance! And that’s with every tool having a _99%_ chance of remaining working (meaning no breaking changes to the tool that affect the build in question).
If we assume a still probably favorable given today’s environment, but slightly lower p of 90%, the graph now looks like this:
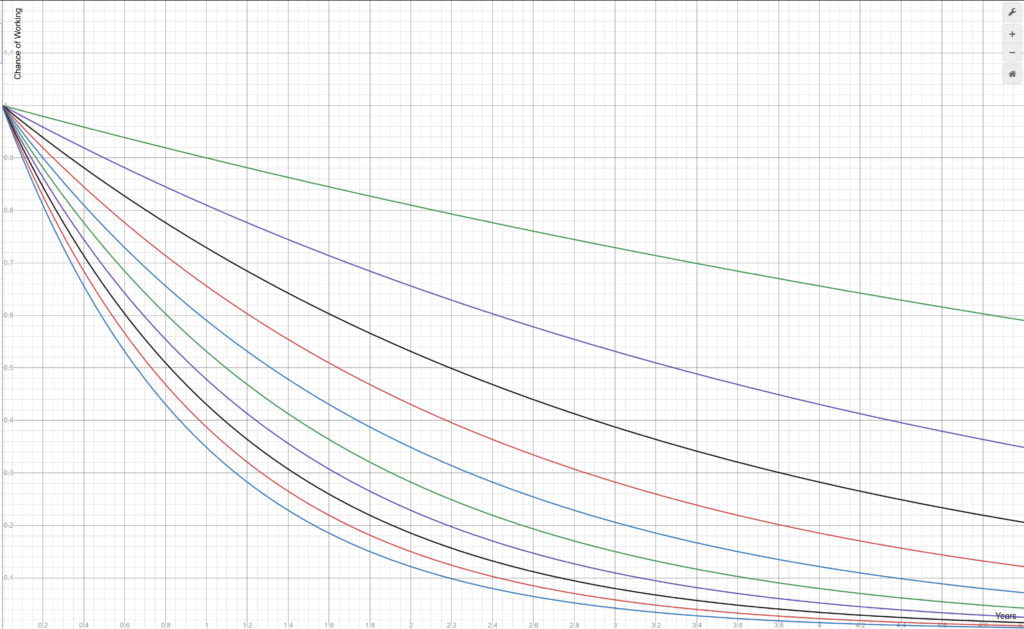
This is, of course, an epic disaster. With just 3 tools used, after 5 years there is _very little chance_ that your codebase will still build correctly. And that’s at 90% and just 3 tools!
If you look at 90%/10 tools, heaven forbid, that bottom line says your build almost certainly doesn’t work after only 2 years… and in fact has barely a 30% chance of working after just 1 year!
Now imagine that we don’t say “tool”. We just say “dependency”. The equation _remains the same_. Modern codebases often have 10s, 100s, or even 1000s of dependencies! What does that do to this graph?
Here is the graph of 10, 100, and 1000 dependencies, assuming a never-happens-on-github percentage chance of a dependency not breaking your build at 99%:
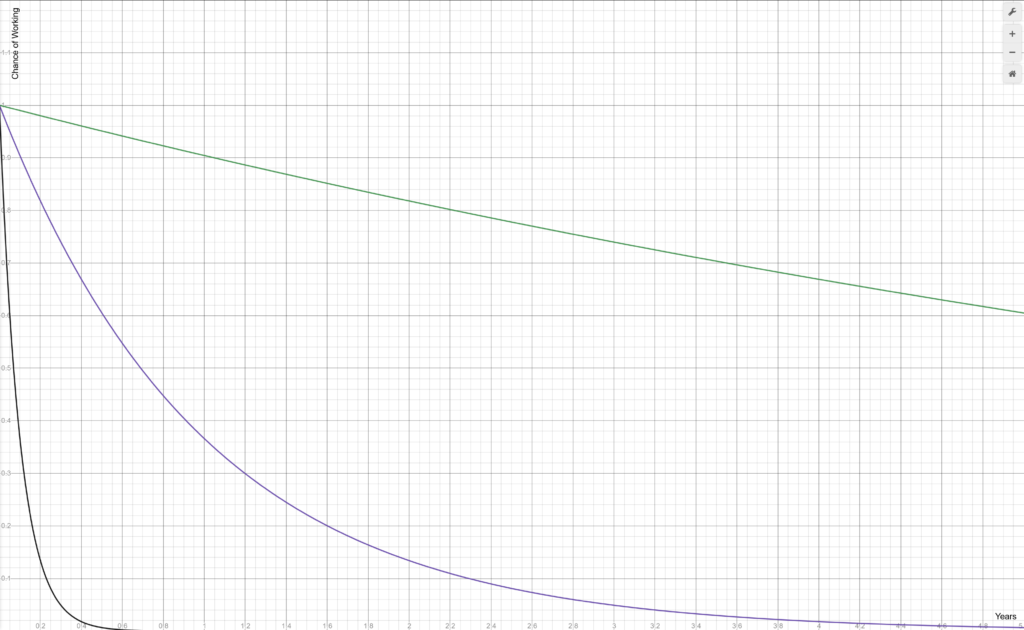
10 dependencies sort-of works. It has a 60% chance of still working after 5 years. 100 dependencies doesn’t work. It’s less than 40% after just 1 year. 1000 dependencies breaks with almost complete certainty after a mere _four months_.
All of this is already something you know intuitively. Projects with lots of dependencies never work out-of-the-box. You are constantly updating, patching, and struggling to get their builds working, because every time something downstream changes, somebody has to fix it.
The “dependency culture” of modern programming has put us into a state where software requires perpetual, constant maintenance. No longer can we take a build and say “this works” and come back to it in a year. Great for job security, horrible for software quality.
As for speculation, I wonder, at least in part, if this answers the questions me and other people like me have, which is how do companies like Twitter employ thousands of developers while seemingly producing almost no additional software or improvements?
Well, if you assume that Twitter’s collective codebase is a 1000+ dependency nightmare, as I assume it probably is, then the math kind of tells us the answer: the vast, vast majority of their time will have to be spent simply keeping their existing code working.
Casey Muratori (@cmuratori)